roll your own base64

We encounter base64 encoding in most of our daily lives (yeah, nerds).
For example, we use base64 encoding to embed image data directly into HTML source code or to prevent the probability of binary data getting corrupt in its raw form when sending attachments over the Internet.
If you’re an active CTF player, you probably see it more than your family already.
Let’s move on to how base64 works without further ado:
ASCII encoding and Base64 encoding are not interchangeable. Don’t fall for this common misunderstanding. They are used for different purposes.
Base64 is a binary-to-text encoding scheme. Therefore, it can encrypt
any binary data or non-ASCII character, and gives ASCII characters
as a result.
Step 1: The Base64 encoding algorithm receives an input stream of 8-bit bytes.
input:
-> oz9un
Binary Represantation(8-bit sequences):
-> 01101111 01111010 00111001 01110101 01101110
Step 2: Split the input into 6-bit chunks. Pad with ‘0’ bits at the end of the last group unless it is split into full 6-bit groups.
Binary Represantation(6-bit sequences):
-> 011011 110111 101000 111001 011101 010110 111000
Step 3: Now that we have 6-bit groups we need to convert them to ASCII characters. But how? By indexing 6-bit sequences into the Base64 index table.
The 6-bit sequences above correspond to:
-> 27 55 40 57 29 22 56
Let’s take a look at the base64 index table
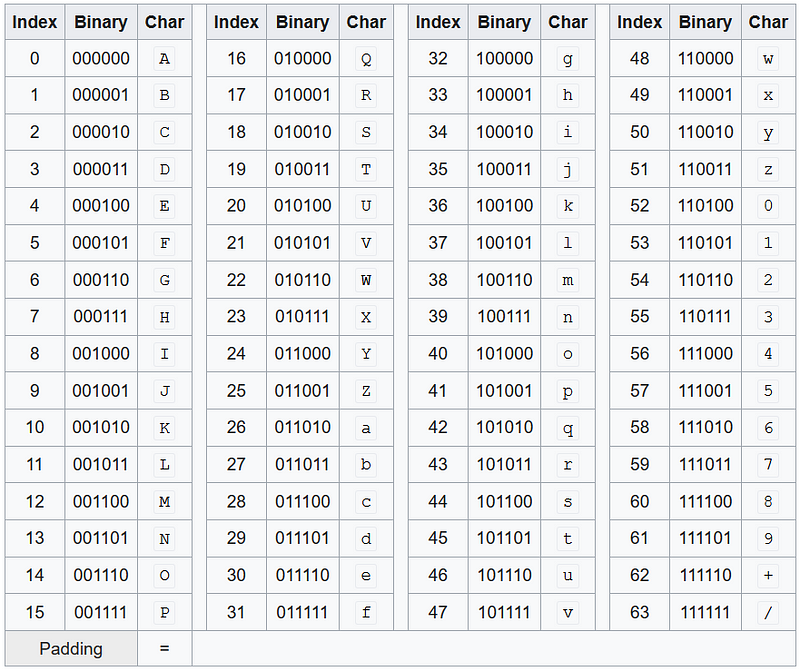
As you can see, there are corresponding ASCII characters for 63 different numbers that 6-bit sequence can take.
What the heck does that ‘Padding’ mean?
Calm, it is for your health. As you may notice, we cut three 8-bit chunks into four 6-bit chunks (that was easy math, got it).
Remember what we did in Step 2. We simply added 0 bits to make sequence splitible into 6-bit chunks. We have two options when adding the ‘0’ bits. Either 2 or 4. And after converting 6-bit sequences into corresponding base64 characters, we should add (# of additional ‘0’ bytes)/2 padding characters(=) at the end of the encoded version.
Okay… can I ask why we did that?
Mmm, I absolutely agree with you. That is unnecessary today. But base64 encoding is very old guy and in its days of youth, computers have limited CPUs/RAMs and writing software was not that easy. So, the decoder guys were thinking of easily splitting the input into 4 blocks and extracting 3 characters from each 4 blocks. And the padding process allowed them to do this without going through the end of the input.
Yeah, that was a sad story. But do not worry. We can code that without needing any padding characters too (we have rams larger than 10mb).
Now it’s time to convert these numbers to ASCII characters with the help of the base64 index table:
The 6-bit sequences above correspond to:
-> 27 55 40 57 29 22 56
Corresponding ASCII characters:
-> b3o5dW4=
And now you definitely have an idea of where this equality sign came from.

Not yet, here we go:
First of all, I can definitely say that we don’t need to import any modules, because we got the logic. That’s the cool part.
Code Step 1: We have to initialize a variable to keep the base64 index table.
[1] You can do that with importing string module. But of course we will not choose this way (code with no imports, thanks).
import string
base64_table = (string.ascii_uppercase+string.ascii_lowercase+string.digits+'+/')
[2] Easy to guess, writing your alphabet yourself will not tire your fingers. But I still leave it for you to copy.
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
digits = '0123456789'
base64_alphabet = ascii_uppercase + ascii_lowercase + digits + '+/'
Code Step 2: Let’s break down our input into 8-bit chunks. (But…We did not take any input. Yeah, take it then.)
to_encode = input("base64 encoder -> ")
chunks_8bit = ''.join([format(bits,'08b') for bits in to_encode.encode('utf8')])

We use format(bits, ‘08b’) to convert an integer to binary keep leading zeros.
With the join, chunks_8bit output looks like:

Code Step 3: It’s time to convert 8-bit chunks to 6-bit chunks and add ‘0’ bits at the end of the string if needed.
chunks_6bit = [chunks_8bit[bits:bits+6] for bits in range(0,len(chunks_8bit),6)]
padding_amount = ( 6 - len(chunks_6bit[len(chunks_6bit)-1]) )
chunks_6bit[len(chunks_6bit)-1] += padding_amount * '0'

This code is all you need to convert 8-bit chunks to 6-bit chunks with ‘0’ padding if needed.
With the help of calculating padding_amount, we can add ‘=’ later.
chunks_6bit output looks like:

Code Step 4: The final step. All we have to do is map these 6-bit chunks value into our base64 alphabet.
encoded = ''.join([base64_alphabet[int(bits,2)] for bits in chunks_6bit])
encoded += int(padding_amount/2) * '='
print('Base64 encoded version of {to_encode} is: {result}'.format(to_encode = to_encode, result = encoded))

We used int(bits,2) to convert binary to decimal. Every two additional ‘0’ bits corresponds to one padding character(‘=’). That is why we divided padding_amount by 2.
Then, we just print it.

You can find the complete code here. As I write new writings, I will share their codes in this repository.
https://github.com/oz9un/crypto_basics/blob/master/base_world/base64_manually.py
The end:

This is at the end of my first post about Crypto Basics. I plan to write much more on this subject as I find time. I would be very happy if you can give a feedback. Stay in touch!
Contact me:
Gmail: [email protected]
Github: https://github.com/oz9un
Twitter: https://twitter.com/oz9un
By Özgün Kültekin on August 23, 2020.